Optimizing JSON, IndexedDB, or postMessage

See that image? … wondering what is this all about?
Well, let me start with the TL;DR: those two are snapshots of the very same data stored in an IndexedDB instance … on the left, we have the usual careless, or lazy way, to store data we’re all used to, resulting into 13MB of disk space, while on the right, a different approach that uses just 5MB and will:
- make both saving and retrieving data faster: a Performance winner
- use way less memory once data is retrieved: a Mobile platform winner
- make data more useful out of the box: a Program’s logic winner
In order to fully grasp what’s going on, what have I done, or how that’s even possible, we need to understand what is the underlying problem I’ve tried to solve.
Let’s start small though …
To better understand where I come from, or where I’m going, please open a new incognito browser with a memory profiler, such as Chromium, and type the following in its console, then take a memory snapshot:
self.a = {some: "value"};
self.b = JSON.parse(JSON.stringify(a));
self.c = {some: a.some + b.some};Now create a new window/tab, and type this instead:
self.a = {some: "value"};
self.b = a; // assign by reference
self.c = {some: a.some + b.some};If you took a memory snapshot in both cases, and you found the String entry, here it’s likely what you’ll read:

I can hear you already mumbling, or screaming, something like:
… of course it’s different, you fool, there’s an object by reference there …
… and that, my friends, is precisely what I am talking about here: the most overlooked issue around the fact serialized, and de-serialized values, creates a lot of undesired extra references behind the JS scene, where in this case is a new object literal, but also, a new string, even if identical to one already known.
Not only JSON
The most important fact to consider here, is that it’s not a JSON issue, per se, rather an issue that involves any kind of de/serialization:
- store those values in IndexedDB? you got it!
- pass those values via postMessage? you got it!
…and so on and so forth, every time some sort of de/serialization is in our way, this issue pops up carelessly, because that’s how the engine works behind the scene, and there’s literally nothing we can control or do about, unless we change the way we store, de/serialize, or postMessage data.
Not only strings neither
For clarity sake, I will focus the rest of this post on strings, as these are the most common, or universal, kind of data we can deal and transfer daily, but while everyone is obsessed with recursion issues when such data is passed around, please bear in mind this issue is the same with objects too:
const mario = {name: "it's a me"};
const luigi = {name: "Luigi!"};
const rules = [
{
match: "something",
applyTo: [mario]
},
{
match: "something-else",
applyTo: [mario, luigi]
},
];Now, the moment we will JSON.stringify(rules), the reference to mario or luigi, as unique identity, will be lost, even if no recursion happens there, and on top of that, the moment we will JSON.parse(stringified)values, mario name will be duplicated, in terms of memory consumption, across all rules that pointed at mario in the first place.
Thanks gosh, when it comes to object same reference, flatted already solved that, and yet, regarding possible data duplication, within objects, it still can’t do much … so that this topic remains an unresolved issue for memory usage, JSON outcome, parsing performance, and so on.
About some real world use case
Maybe not everyone knows that I work mostly behind the AdBlock Plus extension, and like every other Ads blocker, we deal with hundred thousands filters provided by the awesome community around ads blockers, so that optimizing what we store, or retrieve, is simply part of our daily goal and challenge to “make it fast!”.
Filters syntax have the ability to define each domain they’re targeting, but inevitably, such syntax leads to tons of different strings derived from different bigger strings, we all need to parse, assign, and so on, to guarantee each string has been already processed, or not.
Now, I don’t really want to bother you why dealing with the same, yet different, string, is important, but I’d like to point you at the incoming standard, around Web extensions, that is the Manifest v3 API.
Most notably, is the Declarative Network Request API that we’ll need to deal with, in order to comply with this new API requirements.
Let’s look at a basic example:
{
"id" : 1,
"priority": 1,
"action" : { "type" : "block" },
"condition" : {
"urlFilter" : "abc",
"domains" : ["foo.com"],
"resourceTypes" : ["script"]
}
}This literal is a single rule, that describes a condition field able to target multiple domains as well as multiple resource types.
It’s a classic “one to (repeated) many” relationship, because similar domains will be all over other rules, and so will be resource types, and we are talking about hundred thousand rules there, plus thousand of dynamic rules … and here is where memory consumption, beside de/serializing performances, come to mind … but how could we solve the redundancy of information that JSON, IndexedDB, or postMessage, implicitly carry along?
Indexing each Value
While referenced objects and strings have no concrete memory issue, when we store, stringify, or post these values, all these entries are likely creating a duplicated of the same entry that comes from the original environment running the code.
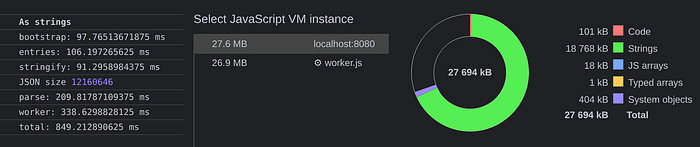
This scenario represents something like:
worker.postMessage({domains, rules});where domains is a unique collection of all domains that are part of the logic, and rules is a list of random rules where, per each rule, there’s one or more domain related by reference, and resourceTypes could be easily part of the game too … however … the moment that literal is either de/serialized or posted, the receiving tab, worker, environment, will inevitably replicate all strings all over, holding the original amount of memory, in a way or another.
Indexing in a nutshell
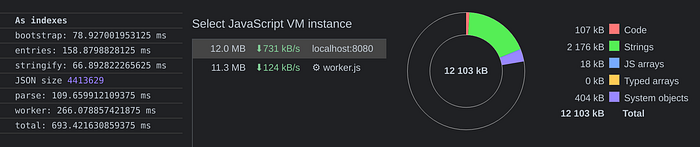
Taking the previous Rules, as example, this is how it’d look now:
{
"id" : 1,
"priority": 1,
"action" : { "type" : "block" },
"condition" : {
"urlFilter" : "abc",
"domains" : [12],
"resourceTypes" : [3]
}
}In short, both list of possibilities are represented by single, unsigned, integers, as opposite of repeating the same domain string, or the same resource type, all over the storage, postMessage, or JSON, format.
Once again, we are talking about avoid repeating the creation of the very same string, or any other reference, across “traveling dances”, that would result in duplicating all of these reference without even thinking about it!
Please bear in mind this is not just a recursion issue, this is rather about having the ability to reproduce the same reference, recursive or not, in multiple parts of the data we’re trying to de/serialize: in JSON, like in IndexedDB, or postMessage, dances, across workers and frames.
Set: A natural primitive
A unique collection is better represented, for both performance reasons and ad-hoc API, by a Set.
const domains = new Set;// parse some filter and then
domains.add(currentOne);
A Set grants uniqueness, so that all we need now, is to relate that domain as index, which works perfectly with ever-growing list of unique values, where an index won’t, or can’t, possibly change value.
In short, we need some bound reference that results into that domain index, but it’s able to keep enriching domains as needed:
const subdomains = domains.bindValues([some, domain]);Now, subdomains also works best as Set reference, but what if it produces indexes from the main Set it comes from?
I know, it sounds confusing, but the idea behind the indexed-values module/helper, is to simplify te relation between unique collections of values, and their main representation, through indexes, and ever growing Set, of such values, so that everything is blazing fast, and the source of truth is a single Set:
import {IndexedValues} from 'indexed-values';const domains = new IndexedValues([one, orMore, domain]);const sub = domains.bindValues([orMore]);// sub is reflected in domains after insertion
if (sub.has(someOther))
sub.add(someOther);
In case it’s needed to explain what domains will be, and what sub also will represent, this is the result:
domains == ["one.it", "or-more.com", "doma.in", "some-other.es"];sub == [1, 3];
See that? domains keeps growing in unique values, never repeated across the data, and sub simply represents indexes, so that once domains and sub are posted, and both entries revived, no duplicated strings, or objects, will bloat the RAM.
Even simpler …
Because I am pretty sure not everything clicked yet, this is the most basic scenario we are talking about:
// current, common, status
const travelingData = [
{"what": ["one"]},
{"what": ["one", "or-more"]},
{"what": ["or-more", "value"]}
];// improvement
const travelingData = {
"what": ["one", "or-more", "value"],
"data": [
{"what": [0]},
{"what": [0, 1]},
{"what": [2]}
]
};
So, indexed-values helps reaching that goal, so that once data travels around, or it’s parsed, after being stringified, we move from this situation:

to this one:

increasing both parsing and traveling performance, and reducing memory consumption.
As Summary
If you have data that contains one-to-many relations and you store such data without any kind of optimization, there’s a huge chance you can improve performance and memory consumption simply by using a smarter approach before serialization, and after it, as revival, winning overall across all metrics, and the indexed-values module could simplify a lot the whole process 👍
