hyperHTML: A Virtual DOM Alternative

Update
Don’t miss latest news on hyperHTML v1 and its growing popularity
Who already knows me, most likely knows my good old post entitled: The DOM Is NOT Slow, Your Abstraction Is.
Beside my little 2015 rant against over bloated libraries, capable of doing a lot but not always capable to deliver performance where it’s most needed, I’ve tried to demonstrate in those days that with some little code, absolutely rushed and quite possibly unmaintainable, it was possible to target only exact things we wanted to, things being either attributes, classes, and text content per each cell.
The result did actually perform better than anything else I could try.
However …
Not everyone would write code like that, and in all fairness I guess they also shouldn’t, and part of the reasons Virtual DOM was born in the first place were still not properly addressed using that messed up code.
A quick summary of issues, borrowed from the virtual-dom repository:
Manual DOM manipulation is messy and keeping track of the previous DOM state is hard. A solution to this problem is to write your code as if you were recreating the entire DOM whenever state changes. Of course, if you actually recreated the entire DOM every time your application state changed, your app would be very slow and your input fields would lose focus.
I think so far we all agree. Targeting manually text nodes, attributes, inline styles to change or listeners isn’t what we like the most about the Web.
The usage of innerHTML has also made part of the history of the Web:
- it’s deadly simple to trash and sneak any string in
- it’s been a mess since ever due lost handlers, lost referenced nodes, Garbage Collectors that went bananas, etc. etc.
It’s not surprising that most blazoned and modern JS frameworks tried to escape from that burden, with or without innerHTML, and virtual-dom project is no exception.
Following a summary of what it does:
virtual-domallows you to update a view whenever state changes by creating a fullVTreeof the view and then patching the DOM efficiently to look exactly as you described it. This results in keeping manual DOM manipulation and previous state tracking out of your application code, promoting clean and maintainable rendering logic for web applications.
And that’s a hell of an achievement so, hat tip to Virtual DOM affectionados.
But …
When something works and there’s a lot of hype around, most developers settle and celebrate, while few others observe, sometimes maybe just skeptically, and analyze the real-world result.
I let you guess which niche I belong to …
Still The DOM After All
Stating the obvious here, it doesn’t actually matter how much abstraction we put on top, we gonna update that view through the (in)famous, apparently slow and surely naughty, DOM API: no way to escape from that! 😱
On top of that, to use such abstraction we will inevitably end up with more and more dependencies that won’t hurt development but quite surely will hurt production results, and I’m talking about users.

It is indeed not by accident that alternative projects focused on code size and independent functionality came out, and yo-yo is just one of these children of the Virtual DOM era.
The part that didn’t convince me about yo-yo, is its performance: quite bad compared to other alternatives and for what I could test, a no-go for complex layouts on Mobile (and who knows me, also knows I am so crazy about Mobile performance that I even test on real devices … anyway …).
Back to the topic: we have a slow path, which is boring, messy, and a manual tracking of the DOM as solution that ain’t gonna happen any time soon. On the other hand, we want the simplicity of innerHTML to update such view, which is one of the yo-yo achievements through template literals.

Close enough, but not quite there yet. How about we use template literals, and we completely drop the whole Virtual DOM bit targeting directly affected nodes, through similar innerHTMLusage simplicity?
hyperHTML To The Rescue
Already starred by 8 developers without me even mentioning it on Twitter, hyperHTML is my latest creation that fits in less than 1.5KB “minzipped”, it delivers performance comparable to the manual mess I’ve written in 2015, and its source code targets every browser new and old.
The tick time? Only the text will change its value. The article? Only its parts will get updated when needed.
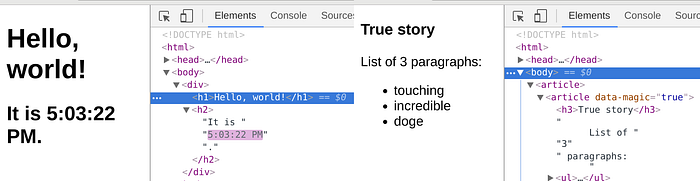
… and in case you are wondering how can it be possible that it targets old browsers, being based on template literals, I can assure you Babel here will do a great job to bring such functionality in a proper standard way.
hyperHTML in a nutshell
It’s nothing more than a function, that works bound with DOM nodes and fragments as context. You bind your target node once, or even more if you don’t care, and you render the same template literals over and over simply passing new data.
- even attributes? sure, even inline class or V0 listeners such
onclick="${callback}" - both text and html? You got it, and more! Just be sure if you want to pass a fragment, a node, or an HTML content there’s no extra chars around it.
- lists of elements too? Yup, feel free to play with tests and examples, also live, but not transpiled (yet), on this page.
It’s “Literally”. Deadly. Simple.
I’m also open for suggestions and use cases I haven’t thought about yet so please let me know what you think about hyperHTML, thank you! ♥️
